 Awesome-Deep-Learning-Resources
Awesome-Deep-Learning-Resources
Resource collection
A curated list of favorite deep learning resources for revisiting topics or reference
Rough list of my favorite deep learning resources, useful for revisiting topics or for reference. I have got through all of the content listed there, carefully. - Guillaume Chevalier

2k stars
119 watching
292 forks
last commit: over 2 years ago
Linked from 7 awesome lists
awesomeawesome-listcnndeep-learninglstmmachine-learningtensorflow
Awesome Deep Learning Resources / Online Classes | |||
| Machine Learning by Andrew Ng on Coursera | Renown entry-level online class with . Taught by: Andrew Ng, Associate Professor, Stanford University; Chief Scientist, Baidu; Chairman and Co-founder, Coursera | ||
| Deep Learning Specialization by Andrew Ng on Coursera | New series of 5 Deep Learning courses by Andrew Ng, now with Python rather than Matlab/Octave, and which leads to a | ||
| Deep Learning by Google | Good intermediate to advanced-level course covering high-level deep learning concepts, I found it helps to get creative once the basics are acquired | ||
| Machine Learning for Trading by Georgia Tech | Interesting class for acquiring basic knowledge of machine learning applied to trading and some AI and finance concepts. I especially liked the section on Q-Learning | ||
| Neural networks class by Hugo Larochelle, Université de Sherbrooke | Interesting class about neural networks available online for free by Hugo Larochelle, yet I have watched a few of those videos | ||
| GLO-4030/7030 Apprentissage par réseaux de neurones profonds | This is a class given by Philippe Giguère, Professor at University Laval. I especially found awesome its rare visualization of the multi-head attention mechanism, which can be contemplated at the | ||
| Deep Learning & Recurrent Neural Networks (DL&RNN) | The most richly dense, accelerated course on the topic of Deep Learning & Recurrent Neural Networks (scroll at the end) | ||
Awesome Deep Learning Resources / Books | |||
| Get back to the basics you fool! Learn how to do Clean Code for your career. This is by far the best book I've read even if this list is related to Deep Learning | |||
| Clean Coder | Learn how to be professional as a coder and how to interact with your manager. This is important for any coding career | ||
| How to Create a Mind | The audio version is nice to listen to while commuting. This book is motivating about reverse-engineering the mind and thinking on how to code AI | ||
| Neural Networks and Deep Learning | This book covers many of the core concepts behind neural networks and deep learning | ||
| Deep Learning - An MIT Press book | Yet halfway through the book, it contains satisfying math content on how to think about actual deep learning | ||
| Some other books I have read | Some books listed here are less related to deep learning but are still somehow relevant to this list | ||
Awesome Deep Learning Resources / Posts and Articles | |||
| List of mid to long term futuristic predictions made by Ray Kurzweil | |||
| The Unreasonable Effectiveness of Recurrent Neural Networks | MUST READ post by Andrej Karpathy - this is what motivated me to learn RNNs, it demonstrates what it can achieve in the most basic form of NLP | ||
| Neural Networks, Manifolds, and Topology | Fresh look on how neurons map information | ||
| Understanding LSTM Networks | Explains the LSTM cells' inner workings, plus, it has interesting links in conclusion | ||
| Attention and Augmented Recurrent Neural Networks | Interesting for visual animations, it is a nice intro to attention mechanisms as an example | ||
| Recommending music on Spotify with deep learning | Awesome for doing clustering on audio - post by an intern at Spotify | ||
| Announcing SyntaxNet: The World’s Most Accurate Parser Goes Open Source | Parsey McParseface's birth, a neural syntax tree parser | ||
| Improving Inception and Image Classification in TensorFlow | Very interesting CNN architecture (e.g.: the inception-style convolutional layers is promising and efficient in terms of reducing the number of parameters) | ||
| WaveNet: A Generative Model for Raw Audio | Realistic talking machines: perfect voice generation | ||
| François Chollet's Twitter | Author of Keras - has interesting Twitter posts and innovative ideas | ||
| Neuralink and the Brain’s Magical Future | Thought provoking article about the future of the brain and brain-computer interfaces | ||
| Migrating to Git LFS for Developing Deep Learning Applications with Large Files | Easily manage huge files in your private Git projects | ||
| The future of deep learning | François Chollet's thoughts on the future of deep learning | ||
| Discover structure behind data with decision trees | Grow decision trees and visualize them, infer the hidden logic behind data | ||
| Hyperopt tutorial for Optimizing Neural Networks’ Hyperparameters | Learn to slay down hyperparameter spaces automatically rather than by hand | ||
| Estimating an Optimal Learning Rate For a Deep Neural Network | Clever trick to estimate an optimal learning rate prior any single full training | ||
| The Annotated Transformer | Good for understanding the "Attention Is All You Need" (AIAYN) paper | ||
| The Illustrated Transformer | Also good for understanding the "Attention Is All You Need" (AIAYN) paper | ||
| Improving Language Understanding with Unsupervised Learning | SOTA across many NLP tasks from unsupervised pretraining on huge corpus | ||
| NLP's ImageNet moment has arrived | All hail NLP's ImageNet moment | ||
| The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) | Understand the different approaches used for NLP's ImageNet moment | ||
| Uncle Bob's Principles Of OOD | Not only the SOLID principles are needed for doing clean code, but the furtherless known REP, CCP, CRP, ADP, SDP and SAP principles are very important for developping huge software that must be bundled in different separated packages | ||
| Why do 87% of data science projects never make it into production? | Data is not to be overlooked, and communication between teams and data scientists is important to integrate solutions properly | ||
| The real reason most ML projects fail | Focus on clear business objectives, avoid pivots of algorithms unless you have really clean code, and be able to know when what you coded is "good enough" | ||
| SOLID Machine Learning | The SOLID principles applied to Machine Learning | ||
Awesome Deep Learning Resources / Practical Resources / Librairies and Implementations | |||
| The best framework for structuring and deploying your machine learning projects, and which is also compatible with most framework (e.g.: Scikit-Learn, TensorFlow, PyTorch, Keras, and so forth) | |||
| TensorFlow's GitHub repository | 186,822 | over 1 year ago | Most known deep learning framework, both high-level and low-level while staying flexible |
| skflow | 3,180 | almost 5 years ago | TensorFlow wrapper à la scikit-learn |
| Keras | Keras is another intersting deep learning framework like TensorFlow, it is mostly high-level | ||
| carpedm20's repositories | Many interesting neural network architectures are implemented by the Korean guy Taehoon Kim, A.K.A. carpedm20 | ||
| carpedm20/NTM-tensorflow | 1,050 | about 9 years ago | Neural Turing Machine TensorFlow implementation |
| Deep learning for lazybones | Transfer learning tutorial in TensorFlow for vision from high-level embeddings of a pretrained CNN, AlexNet 2012 | ||
| LSTM for Human Activity Recognition (HAR) | 3,357 | over 3 years ago | Tutorial of mine on using LSTMs on time series for classification |
| Deep stacked residual bidirectional LSTMs for HAR | 319 | over 3 years ago | Improvements on the previous project |
| Sequence to Sequence (seq2seq) Recurrent Neural Network (RNN) for Time Series Prediction | 1,082 | over 3 years ago | Tutorial of mine on how to predict temporal sequences of numbers - that may be multichannel |
| Hyperopt for a Keras CNN on CIFAR-100 | 106 | about 8 years ago | Auto (meta) optimizing a neural net (and its architecture) on the CIFAR-100 dataset |
| ML / DL repositories I starred | GitHub is full of nice code samples & projects | ||
| Smoothly Blend Image Patches | 0 | almost 9 years ago | Smooth patch merger for |
| Self Governing Neural Networks (SGNN): the Projection Layer | 23 | over 3 years ago | With this, you can use words in your deep learning models without training nor loading embeddings |
| Neuraxle | 610 | about 3 years ago | Neuraxle is a Machine Learning (ML) library for building neat pipelines, providing the right abstractions to both ease research, development, and deployment of your ML applications |
| Clean Machine Learning, a Coding Kata | 18 | over 3 years ago | Learn the good design patterns to use for doing Machine Learning the good way, by practicing |
Awesome Deep Learning Resources / Practical Resources / Some Datasets | |||
| TONS of datasets for ML | |||
| Cornell Movie--Dialogs Corpus | This could be used for a chatbot | ||
| SQuAD The Stanford Question Answering Dataset | Question answering dataset that can be explored online, and a list of models performing well on that dataset | ||
| LibriSpeech ASR corpus | Huge free English speech dataset with balanced genders and speakers, that seems to be of high quality | ||
| Awesome Public Datasets | 61,377 | over 1 year ago | An awesome list of public datasets |
| SentEval: An Evaluation Toolkit for Universal Sentence Representations | A Python framework to benchmark your sentence representations on many datasets (NLP tasks) | ||
| ParlAI: A Dialog Research Software Platform | Another Python framework to benchmark your sentence representations on many datasets (NLP tasks) | ||
Awesome Deep Learning Resources / Other Math Theory / Gradient Descent Algorithms & Optimization Theory | |||
| Overview on how does the backpropagation algorithm works | |||
| Neural Networks and Deep Learning, ch.4 | A visual proof that neural nets can compute any function | ||
| Yes you should understand backprop | Exposing backprop's caveats and the importance of knowing that while training models | ||
| Artificial Neural Networks: Mathematics of Backpropagation | Picturing backprop, mathematically | ||
| Deep Learning Lecture 12: Recurrent Neural Nets and LSTMs | Unfolding of RNN graphs is explained properly, and potential problems about gradient descent algorithms are exposed | ||
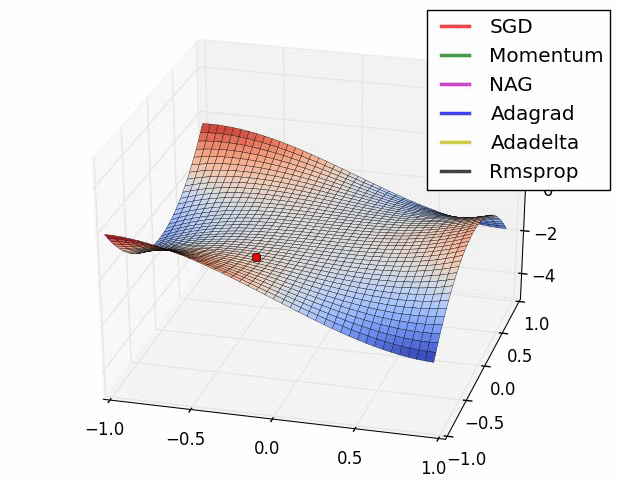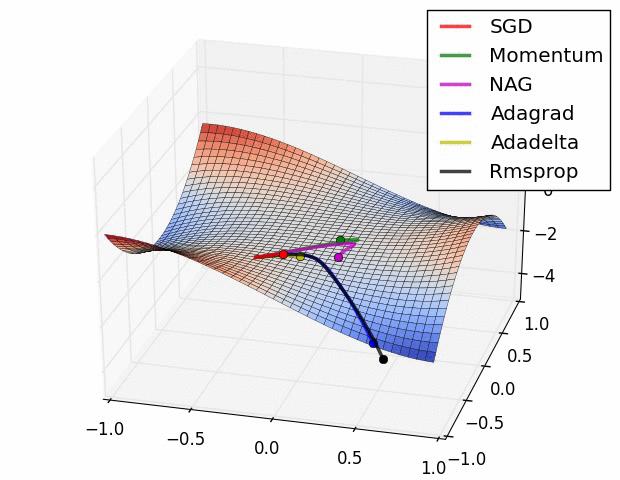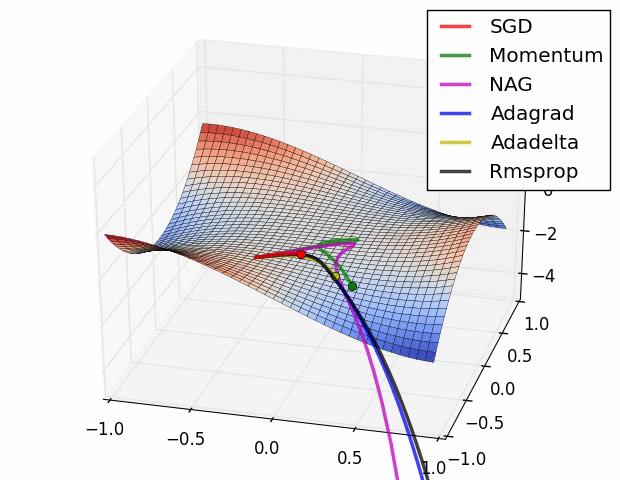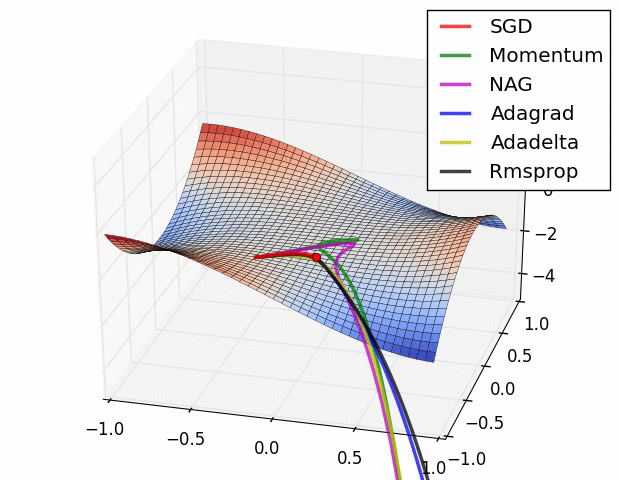
| Gradient descent algorithms in a saddle point | Visualize how different optimizers interacts with a saddle points | ||
| Gradient descent algorithms in an almost flat landscape | Visualize how different optimizers interacts with an almost flat landscape | ||
| Gradient Descent | Okay, I already listed Andrew NG's Coursera class above, but this video especially is quite pertinent as an introduction and defines the gradient descent algorithm | ||
| Gradient Descent: Intuition | What follows from the previous video: now add intuition | ||
| Gradient Descent in Practice 2: Learning Rate | How to adjust the learning rate of a neural network | ||
| The Problem of Overfitting | A good explanation of overfitting and how to address that problem | ||
| Diagnosing Bias vs Variance | Understanding bias and variance in the predictions of a neural net and how to address those problems | ||
| Self-Normalizing Neural Networks | Appearance of the incredible SELU activation function | ||
| Learning to learn by gradient descent by gradient descent | RNN as an optimizer: introducing the L2L optimizer, a meta-neural network | ||
Awesome Deep Learning Resources / Other Math Theory / Complex Numbers & Digital Signal Processing | |||
| Wikipedia page that lists some of the known window functions - note that the is specially interesting for greedy hill-climbing algorithms (like gradient descent for example) | |||
| MathBox, Tools for Thought Graphical Algebra and Fourier Analysis | New look on Fourier analysis | ||
| How to Fold a Julia Fractal | Animations dealing with complex numbers and wave equations | ||
| Animate Your Way to Glory, Math and Physics in Motion | Convergence methods in physic engines, and applied to interaction design | ||
| Animate Your Way to Glory - Part II, Math and Physics in Motion | Nice animations for rotation and rotation interpolation with Quaternions, a mathematical object for handling 3D rotations | ||
| Filtering signal, plotting the STFT and the Laplace transform | 67 | almost 8 years ago | Simple Python demo on signal processing |
Awesome Deep Learning Resources / Papers / Recurrent Neural Networks | |||
| You_Again's summary/overview of deep learning, mostly about RNNs | |||
| Bidirectional Recurrent Neural Networks | Better classifications with RNNs with bidirectional scanning on the time axis | ||
| Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation | Two networks in one combined into a seq2seq (sequence to sequence) Encoder-Decoder architecture. RNN Encoder–Decoder with 1000 hidden units. Adadelta optimizer | ||
| Sequence to Sequence Learning with Neural Networks | 4 stacked LSTM cells of 1000 hidden size with reversed input sentences, and with beam search, on the WMT’14 English to French dataset | ||
| Exploring the Limits of Language Modeling | Nice recursive models using word-level LSTMs on top of a character-level CNN using an overkill amount of GPU power | ||
| Neural Machine Translation and Sequence-to-sequence Models: A Tutorial | Interesting overview of the subject of NMT, I mostly read part 8 about RNNs with attention as a refresher | ||
| Exploring the Depths of Recurrent Neural Networks with Stochastic Residual Learning | Basically, residual connections can be better than stacked RNNs in the presented case of sentiment analysis | ||
| Pixel Recurrent Neural Networks | Nice for photoshop-like "content aware fill" to fill missing patches in images | ||
| Adaptive Computation Time for Recurrent Neural Networks | Let RNNs decide how long they compute. I would love to see how well would it combines to Neural Turing Machines. Interesting interactive visualizations on the subject can be found | ||
Awesome Deep Learning Resources / Papers / Convolutional Neural Networks | |||
| Awesome for the use of "local contrast normalization" | |||
| ImageNet Classification with Deep Convolutional Neural Networks | AlexNet, 2012 ILSVRC, breakthrough of the ReLU activation function | ||
| Visualizing and Understanding Convolutional Networks | For the "deconvnet layer" | ||
| Fast and Accurate Deep Network Learning by Exponential Linear Units | ELU activation function for CIFAR vision tasks | ||
| Very Deep Convolutional Networks for Large-Scale Image Recognition | Interesting idea of stacking multiple 3x3 conv+ReLU before pooling for a bigger filter size with just a few parameters. There is also a nice table for "ConvNet Configuration" | ||
| Going Deeper with Convolutions | GoogLeNet: Appearance of "Inception" layers/modules, the idea is of parallelizing conv layers into many mini-conv of different size with "same" padding, concatenated on depth | ||
| Highway Networks | Highway networks: residual connections | ||
| Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift | Batch normalization (BN): to normalize a layer's output by also summing over the entire batch, and then performing a linear rescaling and shifting of a certain trainable amount | ||
| U-Net: Convolutional Networks for Biomedical Image Segmentation | The U-Net is an encoder-decoder CNN that also has skip-connections, good for image segmentation at a per-pixel level | ||
| Deep Residual Learning for Image Recognition | Very deep residual layers with batch normalization layers - a.k.a. "how to overfit any vision dataset with too many layers and make any vision model work properly at recognition given enough data" | ||
| Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning | For improving GoogLeNet with residual connections | ||
| WaveNet: a Generative Model for Raw Audio | Epic raw voice/music generation with new architectures based on dilated causal convolutions to capture more audio length | ||
| Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling | 3D-GANs for 3D model generation and fun 3D furniture arithmetics from embeddings (think like word2vec word arithmetics with 3D furniture representations) | ||
| Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour | Incredibly fast distributed training of a CNN | ||
| Densely Connected Convolutional Networks | Best Paper Award at CVPR 2017, yielding improvements on state-of-the-art performances on CIFAR-10, CIFAR-100 and SVHN datasets, this new neural network architecture is named DenseNet | ||
| The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation | Merges the ideas of the U-Net and the DenseNet, this new neural network is especially good for huge datasets in image segmentation | ||
| Prototypical Networks for Few-shot Learning | Use a distance metric in the loss to determine to which class does an object belongs to from a few examples | ||
Awesome Deep Learning Resources / Papers / Attention Mechanisms | |||
| Attention mechanism for LSTMs! Mostly, figures and formulas and their explanations revealed to be useful to me. I gave a talk on that paper | |||
| Neural Turing Machines | Outstanding for letting a neural network learn an algorithm with seemingly good generalization over long time dependencies. Sequences recall problem | ||
| Show, Attend and Tell: Neural Image Caption Generation with Visual Attention | LSTMs' attention mechanisms on CNNs feature maps does wonders | ||
| Teaching Machines to Read and Comprehend | A very interesting and creative work about textual question answering, what a breakthrough, there is something to do with that | ||
| Effective Approaches to Attention-based Neural Machine Translation | Exploring different approaches to attention mechanisms | ||
| Matching Networks for One Shot Learning | Interesting way of doing one-shot learning with low-data by using an attention mechanism and a query to compare an image to other images for classification | ||
| Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation | In 2016: stacked residual LSTMs with attention mechanisms on encoder/decoder are the best for NMT (Neural Machine Translation) | ||
| Hybrid computing using a neural network with dynamic external memory | Improvements on differentiable memory based on NTMs: now it is the Differentiable Neural Computer (DNC) | ||
| Massive Exploration of Neural Machine Translation Architectures | That yields intuition about the boundaries of what works for doing NMT within a framed seq2seq problem formulation | ||
| Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions | A used as a vocoder can be conditioned on generated Mel Spectrograms from the Tacotron 2 LSTM neural network with attention to generate neat audio from text | ||
| Attention Is All You Need | (AIAYN) - Introducing multi-head self-attention neural networks with positional encoding to do sentence-level NLP without any RNN nor CNN - this paper is a must-read (also see and of the paper) | ||
Awesome Deep Learning Resources / Papers / Other | |||
| Replace word embeddings by word projections in your deep neural networks, which doesn't require a pre-extracted dictionnary nor storing embedding matrices | |||
| Self-Governing Neural Networks for On-Device Short Text Classification | This paper is the sequel to the ProjectionNet just above. The SGNN is elaborated on the ProjectionNet, and the optimizations are detailed more in-depth (also see my and watch ) | ||
| Matching Networks for One Shot Learning | Classify a new example from a list of other examples (without definitive categories) and with low-data per classification task, but lots of data for lots of similar classification tasks - it seems better than siamese networks. To sum up: with Matching Networks, you can optimize directly for a cosine similarity between examples (like a self-attention product would match) which is passed to the softmax directly. I guess that Matching Networks could probably be used as with negative-sampling softmax training in word2vec's CBOW or Skip-gram without having to do any context embedding lookups | ||
Awesome Deep Learning Resources / YouTube and Videos | |||
| A talk for a reading group on attention mechanisms (Paper: Neural Machine Translation by Jointly Learning to Align and Translate) | |||
| Tensor Calculus and the Calculus of Moving Surfaces | Generalize properly how Tensors work, yet just watching a few videos already helps a lot to grasp the concepts | ||
| Deep Learning & Machine Learning (Advanced topics) | A list of videos about deep learning that I found interesting or useful, this is a mix of a bit of everything | ||
| Signal Processing Playlist | A YouTube playlist I composed about DFT/FFT, STFT and the Laplace transform - I was mad about my software engineering bachelor not including signal processing classes (except a bit in the quantum physics class) | ||
| Computer Science | Yet another YouTube playlist I composed, this time about various CS topics | ||
| Siraj's Channel | Siraj has entertaining, fast-paced video tutorials about deep learning | ||
| Two Minute Papers' Channel | Interesting and shallow overview of some research papers, for example about WaveNet or Neural Style Transfer | ||
| Geoffrey Hinton interview | Andrew Ng interviews Geoffrey Hinton, who talks about his research and breaktroughs, and gives advice for students | ||
| Growing Neat Software Architecture from Jupyter Notebooks | A primer on how to structure your Machine Learning projects when using Jupyter Notebooks | ||
Awesome Deep Learning Resources / Misc. Hubs & Links | |||
| Maybe how I discovered ML - Interesting trends appear on that site way before they get to be a big deal | |||
| DataTau | This is a hub similar to Hacker News, but specific to data science | ||
| Naver | This is a Korean search engine - best used with Google Translate, ironically. Surprisingly, sometimes deep learning search results and comprehensible advanced math content shows up more easily there than on Google search | ||
| Arxiv Sanity Preserver | arXiv browser with TF/IDF features | ||
| Awesome Neuraxle | 1 | about 5 years ago | An awesome list for Neuraxle, a ML Framework for coding clean production-level ML pipelines |
 sindresorhus/awesome
sindresorhus/awesome bayandin/awesome-awesomeness
bayandin/awesome-awesomeness owainlewis/awesome-artificial-intelligence
owainlewis/awesome-artificial-intelligence jnv/lists
jnv/lists endymecy/awesome-deeplearning-resources
endymecy/awesome-deeplearning-resources erichs/awesome-awesome
erichs/awesome-awesome 0ex/more-awesome
0ex/more-awesome{kind=link}
{kind=link}
More related projects:
-
rocm/tensorflow-upstream
-
neuraxio/lstm-human-activity-recognition
-
ibm/max-object-detector
-
-
-
lifeiteng/vall-e
-
tensorflow/models
-
kinhong/openlabeler
-
yuyang-huang/keras-inception-resnet-v2
-
-
-
-
-